Team Food Sovereignty found a nice resource on Food Insecurity from Feeding America.
Here’s the food insecurity dataset in a google sheet
I can’t read directly from this sheet because I don’t have edit access, so I downloaded it to a spreadsheet. I copied to my own sheet. I tried reading it in via googlesheets4 package but that was causing weird errors, so I downloaded a .csv, moved it to the working directory and imported it that way.
I’ll load the janitor library cause the column names on this worksheet are horrible Excel abominations.
food<-read_csv('MMG2022_2020-2019_FeedingAmerica.xlsx - County.csv')%>%##Fix column namesclean_names()%>%##select California data for 2020filter(state=='CA')%>%filter(year==2020)head(food)
# A tibble: 6 × 23
fips state county_state year overall_food_insecur…¹ number_of_food_insec…²
<dbl> <chr> <chr> <dbl> <chr> <dbl>
1 6001 CA Alameda Count… 2020 9.3% 154830
2 6003 CA Alpine County… 2020 11.7% 140
3 6005 CA Amador County… 2020 10.6% 4160
4 6007 CA Butte County,… 2020 14.0% 31330
5 6009 CA Calaveras Cou… 2020 11.4% 5240
6 6011 CA Colusa County… 2020 12.9% 2760
# ℹ abbreviated names: ¹overall_food_insecurity_rate_1_year,
# ²number_of_food_insecure_persons_overall_1_year
# ℹ 17 more variables:
# food_insecurity_rate_among_black_persons_all_ethnicities <chr>,
# food_insecurity_rate_among_hispanic_persons_any_race <chr>,
# food_insecurity_rate_among_white_non_hispanic_persons <chr>,
# low_threshold_in_state <chr>, low_threshold_type <chr>, …
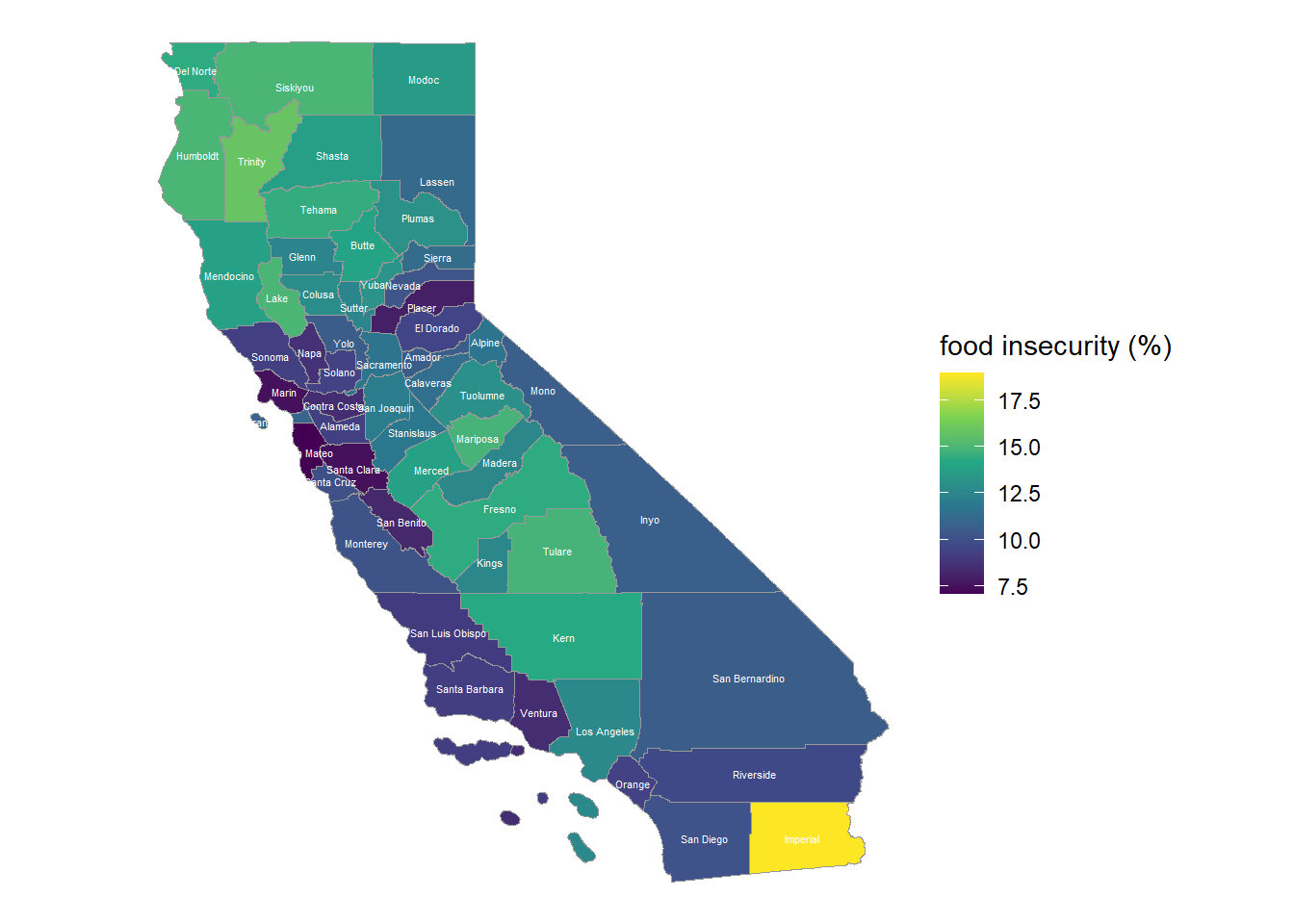
We can add that to a map, if we had a shapefile of California counties. The California open data portal has that info.
Doing this one time, point and click is ok. Here are the steps.
Download the zipped shapefile (not code)
Move it to your working directory (not code)
Unzip/extract the zip file (code or not code - your choice)
Dataset CA_county has the geospatial information. Dataset food has the food insecurity data but doesn’t have the geospatial information included.
Putting the two datasets together is required to make the map to show spatial patterns in food insecurity. Both datasets have a field that indicates the County Name. The tidyversedplyr package has functions to join datasets by common variables.
inner_join() - keep only records present in both datasets.
left_join() - keep all records from the first dataset and only matching variables from the second. Fill missing with NA
right_join() - keep all records from the second dataset and only matching variables from the first. Fill missing with NA
full_join() - keep all records both datasets - fill NA in any records where dataset is missing from one of the datasets.
anti_join() - keep only records in the first dataset that don’t occur in the second dataset.
Join Venn Diagrams - credit Tavareshugo github
For the county case, California has 58 counties, but I will try an inner join to make sure that every county name matches.
Note, the food dataset had an extra bit of text in its county column, we’ll use a tiny bit of language parsing to chop that out so the columns will match exactly.
The string we need to remove is County, California. The function we want is str_remove() from stringr part of the base tidyverse.
food2<-food%>%mutate(county =str_remove(county_state, ' County, California'))food2$county
TRI_2021<-read_csv('2021_us.csv')%>%janitor::clean_names()%>%filter(x34_chemical=='Ethylene oxide')%>%select(x4_facility_name, x6_city, x12_latitude, x13_longitude, x48_5_1_fugitive_air, x49_5_2_stack_air, x62_on_site_release_total)%>%rename(facility =x4_facility_name, city =x6_city, lat =x12_latitude, lng =x13_longitude, emissions =x62_on_site_release_total)
Warning: One or more parsing issues, call `problems()` on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)
Rows: 76568 Columns: 119
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (27): 2. TRIFD, 4. FACILITY NAME, 5. STREET ADDRESS, 6. CITY, 7. COUNTY,...
dbl (86): 1. YEAR, 3. FRS ID, 10. BIA, 12. LATITUDE, 13. LONGITUDE, 19. INDU...
lgl (6): 21. PRIMARY SIC, 22. SIC 2, 23. SIC 3, 24. SIC 4, 25. SIC 5, 26. S...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.